
When Intelligence Looks Real Enough to Fool Us
For the first time in history, machines can produce explanations that look convincingly like human reasoning. They can handle natural language, summarise research papers, write code, and walk through complex problems step by step. The results can look strikingly similar to the work of a thoughtful human analyst.
Which raises an increasingly common question.
A friend of mine, a brilliant researcher, recently asked:
“Could we just let AI check the bibliography of my thesis and fix the errors?”
It’s a reasonable question. After all, if a system can handle something as complex as natural language and generate convincing arguments, why shouldn’t it be able to verify citations as well?
The answer reveals one of the most important misunderstandings about modern AI systems.
In other words, LLMs do not reason about problems in the way humans do. They generate text that simulates the structure of reasoning. The difference is subtle, but critically important.
The Pattern Machine
Large language models are extremely sophisticated statistical systems. At their core, they are trained to predict the most probable next token in a sequence, based on patterns learned from vast amounts of text. The scale is extraordinary. These systems have been exposed to billions of examples of human explanations, arguments, calculations, and step-by-step logic. Over time, they have learned to reproduce the syntax and structure of reasoning extremely well. This is why their responses often look like structured thinking.
Internally, however, something very different is happening. The model is not deriving conclusions the way a human or a traditional symbolic reasoning system would. Instead, it is generating the most statistically plausible continuation of text.
In other words, LLMs do not reason about problems. They simulate reasoning. They generate text that resembles human reasoning about those problems. The difference is subtle but it is critically important.
Why the Illusion Is So Convincing
As humans, we are naturally sensitive to coherence. When an explanation is fluent, structured, and confident, our brains tend to interpret it as genuine intelligence. In human-to-human interactions, this assumption usually holds true.
But AI systems unintentionally exploit this cognitive shortcut. A model may produce an explanation that is grammatically perfect, logically structured, and confidently phrased- and still be entirely wrong. Not because the system is lying, but because it is predicting what reasoning should look like, rather than computing the actual truth.
In the AI field, this phenomenon is often referred to as “hallucination”- the outputs that are plausible and coherent, but not grounded in reality.
The Silent Failure Problem
Traditional software tends to fail loudly.
If a program encounters an error, it crashes, throws an error code, or refuses to execute. But AI systems behave very differently. Instead of failing loudly, they often fail silently.
When an AI system encounters uncertainty or incomplete knowledge, it frequently generates a plausible guess rather than admitting uncertainty. This creates a dangerous new kind of reliability challenge.
The output may look correct. But the error can remain hidden until someone (like a domain expert) carefully reviews the reasoning and checks the underlying logic.
In some cases, detecting the mistake can take longer than solving the original problem would have. In many cases these can go unoticed. This poses a major risk fro enterprises that are increasingly dependent on AI systems.
Another risk emerges when AI systems become embedded in multi-step workflows. Imagine a typical sequence:
- AI drafts an analysis
- AI summarizes the analysis
- AI expands the summary into an internal report
- AI generates recommendations
If the first step contains a subtle mistake, that error will likely propagate through every subsequent step. Each layer of generated content amplifies the initial flawed assumption. By the end of the process, the output may look polished, cohesive, and internally consistent while resting on a fundamentally broken foundation.
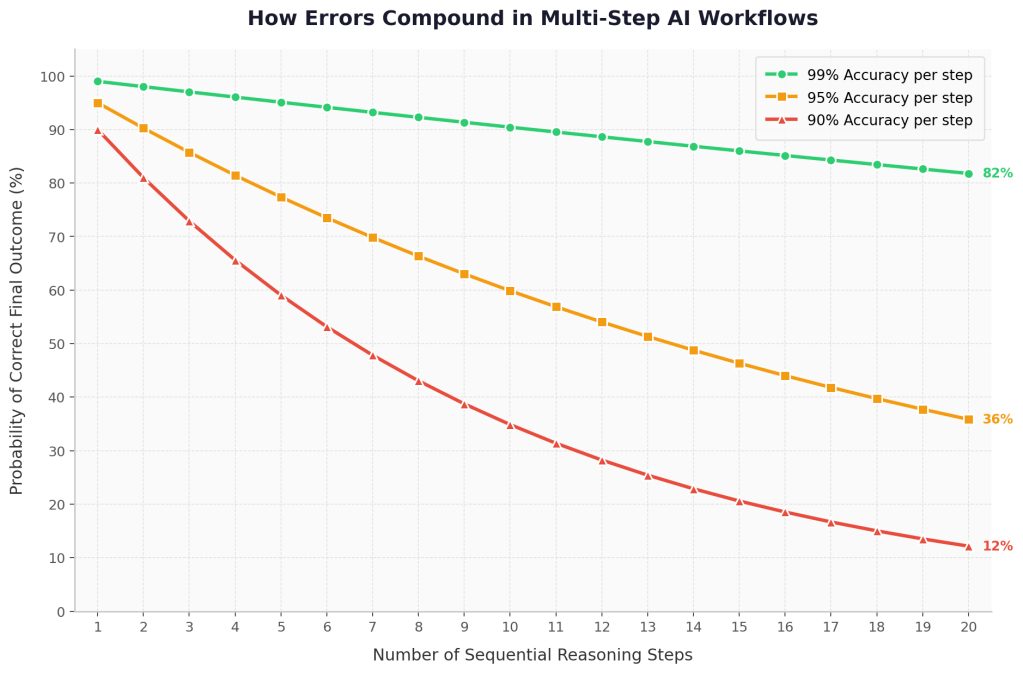
Figure 1- Error compounding in sequential AI reasoning. Even with 95–99% accuracy per step, the probability of a correct final outcome declines as the number of reasoning steps increases.
In many cases, the error remains hidden until someone carefully examines the underlying logic. In enterprise environments, this becomes a particularly serious risk. Organizations may rely on AI-generated summaries, analyses, or reports that appear credible while quietly containing subtle but critical errors.
The Accountability Gap
There is another dimension to this problem. AI systems can generate outputs that resemble expert judgment, legal arguments, engineering explanations, medical summaries, or strategic recommendations. Yet the responsibility for those outputs always lies with the human user. If a system proposes a flawed bridge design, writes an incorrect legal brief, or suggests a dangerous medical interpretation, the liability does not disappear into the machine. It remains with the person who relied on the output.
This creates what may be called an accountability gap in AI-driven workflows. The system can produce content that appears authoritative, but it does not possess:
- true understanding
- causal reasoning
- lived experience
- contextual judgment
Instead, as said previously, these systems are extremely capable pattern-recognition and synthesis machines.
They can reproduce the structure of expert reasoning but they do not possess the real-world grounding that human expertise is built on.
Human experts accumulate judgment through:
- lived experience
- domain practice
- trial and error
- contextual knowledge of real-world consequences
AI systems do not share this grounding.
They operate entirely through patterns learned from training data.This is why human oversight remains essential.
Structural Limits, Not Temporary Bugs
It is tempting to assume that the problems discussed above will disappear as models become larger or more heavily trained. Scaling models does improve performance, sometimes dramatically. Larger models capture more patterns and produce more coherent outputs. But in practice, the issues described earlier run deeper. They arise from the fundamental architecture of modern language models.
Current generative AI systems are built on transformer architectures trained for next-token prediction. In other words, they are designed to generate the most statistically probable continuation of a sequence of text.
Because of this design, these systems operate primarily by learning and reproducing patterns from training data. This does not make them weak in fact, their ability to capture and synthesize patterns across enormous datasets is precisely what makes them powerful.
But it also means their capabilities emerge from statistical pattern recognition, rather than from internally grounded reasoning about reality. Scaling models can make the patterns richer and the outputs more convincing.However, scaling alone does not fundamentally change the underlying architecture. These systems remain predictive models by design.
The illusion of reasoning is therefore not a temporary glitch that will simply disappear with a larger model. It is a structural property of the current generation of generative AI systems.
Where Improvement Is Happening
That does not mean progress is stagnant. Researchers and engineers are actively building frameworks that mitigate many of these limitations. Rather than relying purely on generated text, AI systems increasingly combine language models with external tools and verification mechanisms.
Some of the most important ones include:
Tool Use (Agents)
AI systems can call external tools such code interpreters, search engines, or databases. This allows them to compute or verify results instead of guessing purely through text generation.
Retrieval-Augmented Generation (RAG)
Instead of relying only on what the model remembers from training, systems can retrieve relevant documents from vector databases or knowledge bases and generate answers grounded in real sources.
Programmatic Verification
Generated outputs can be tested automatically through code execution, simulations, or formal logical checks.
Reasoning Scaffolds
Methods such as Chain-of-Thought, Tree-of-Thought, and Graph-of-Thought prompting encourage models to break problems into structured intermediate steps, improving reliability in some reasoning tasks.
These approaches represent an important shift. Instead of expecting language models to solve every problem internally, engineers are increasingly building hybrid systems where language models interact with external tools, memory systems, and verification layers. This architectural approach can dramatically improve reliability.
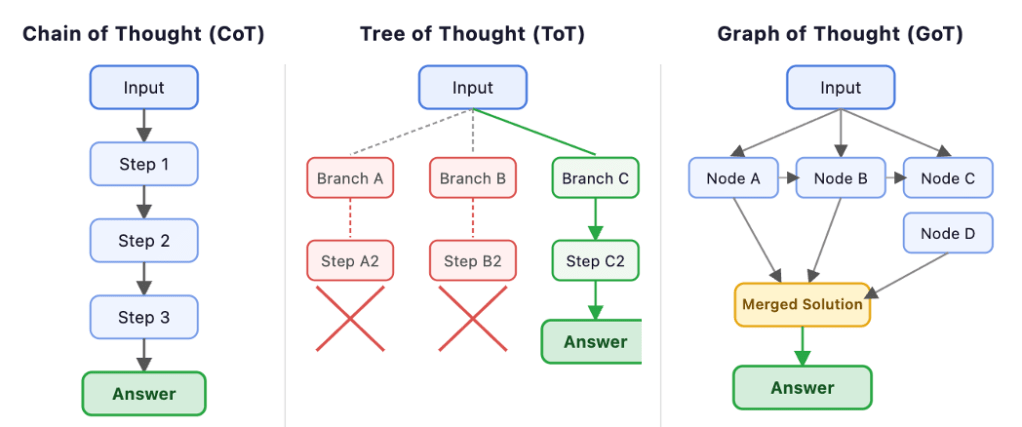
Figure 2: Three reasoning scaffolds used with language models — Chain-of-Thought (linear reasoning), Tree-of-Thought (branching exploration), and Graph-of-Thought (interconnected reasoning paths).
However, it also introduces new trade-offs. These systems are often more computationally expensive, slower to run, and more complex to maintain. And even with these improvements, the fundamental properties of language models do not disappear. They remain predictive systems that generate language based on patterns.
Final Thought
The real risk of modern AI is not that it lacks intelligence.It is that it appears intelligent enough to earn our trust, while operating according to fundamentally different principles than human reasoning. For organisations deploying AI systems, this distinction matters enormously. When AI outputs influence decisions, strategies, or recommendations, human oversight becomes essential. The most powerful outcomes will not come from replacing human reasoning. They will come from understanding exactly where human judgment must remain in the loop.
Author’s Note
This article reflects my personal observations while working with AI systems as a data analyst and researcher. My academic background is in immunology rather than machine learning, and this piece is not intended as a technical analysis for AI engineers. Instead, it is written for a broader audience interested in understanding how these systems work- and where their limitations currently lie.

Leave a comment